Software development estimation is incredibly challenging. Despite careful planning, projects often run over budget, miss deadlines, and face unexpected roadblocks. A study by McKinsey found that, on average, tech projects go 45% over budget and 7% past their deadlines. The impact is even greater for large-scale software projects—those with budgets exceeding $15 million saw cost overruns of 66% on average, with schedule delays reaching 33%.
These inaccuracies lead to wasted resources, frustrated teams, and dissatisfied stakeholders. A simple oversight—like an underestimated dependency or a minor requirement change—can snowball into weeks of delays.
Software estimation may never be perfect, but it can always be improved. With experience from over 200 tech projects, we’ve seen firsthand numerous situations go off track —and how to make them better. Let’s dive into how you can refine the process and avoid common pitfalls.
Why software development estimation is difficult to get right
In software development, you must account for various factors—including technology, people, requirements, and external dependencies—each with its own uncertainties.
Technology
Technology is inherently complex, with countless programming languages, libraries, and tools. Unexpected challenges often arise when integrating these components. A simple five-minute task, like upgrading a library, can quickly spiral into two days of work due to compatibility issues with other dependencies, requiring further modifications and additional testing. Even a small typo in the code can lead to hours of debugging, making precise software development estimation complex
People
People’s productivity isn’t always consistent, yet software project estimation often assumes equal competence and a steady work pace, regardless of fatigue, frustration, or illness. But reality doesn’t work that way. Interruptions are inevitable, and sometimes, a team member needs to spend an hour or two assisting a colleague—which isn’t a drawback, but a valuable part of collaboration.
Requirements
Requirements can be unclear or evolve as new information emerges—and that’s a natural part of the process. If a developer begins working on a requirement and realizes something doesn’t add up, they need clarification. But what if the right person is unavailable, on leave, or tied up in meetings all day? That waiting time causes delays, meaning a single unanswered question can throw off an entire software estimation
External dependencies
External dependencies are even harder to control than changing requirements. When relying on external vendors, organizations are bound by their SLAs for issue resolution. If the dependency is an API, it adds multiple potential points of failure—whether it’s our servers, the vendor’s servers, or the network components in between—any disruption can lead to delays.
Thus, estimating the effort or time required for a project often feels unreliable, so why bother at all? In fact, there has been a rise in the #NoEstimates movement which advocates for eliminating software development estimation entirely. This raises a bold question:
Do we really need software development estimation?
While we all know that software estimation is incredibly difficult to get right, there are times when having a clear answer—ideally an accurate one—is essential. Sales may need a committed timeline to close a major deal. A feature might be a critical dependency for another team, requiring a schedule to align their work. Or it could be part of a larger product launch, where marketing and operations need a timeline to plan effectively. The list goes on, but the key takeaway is this: in many situations, a software development estimation isn’t just helpful—it’s essential.
Software development estimation technique
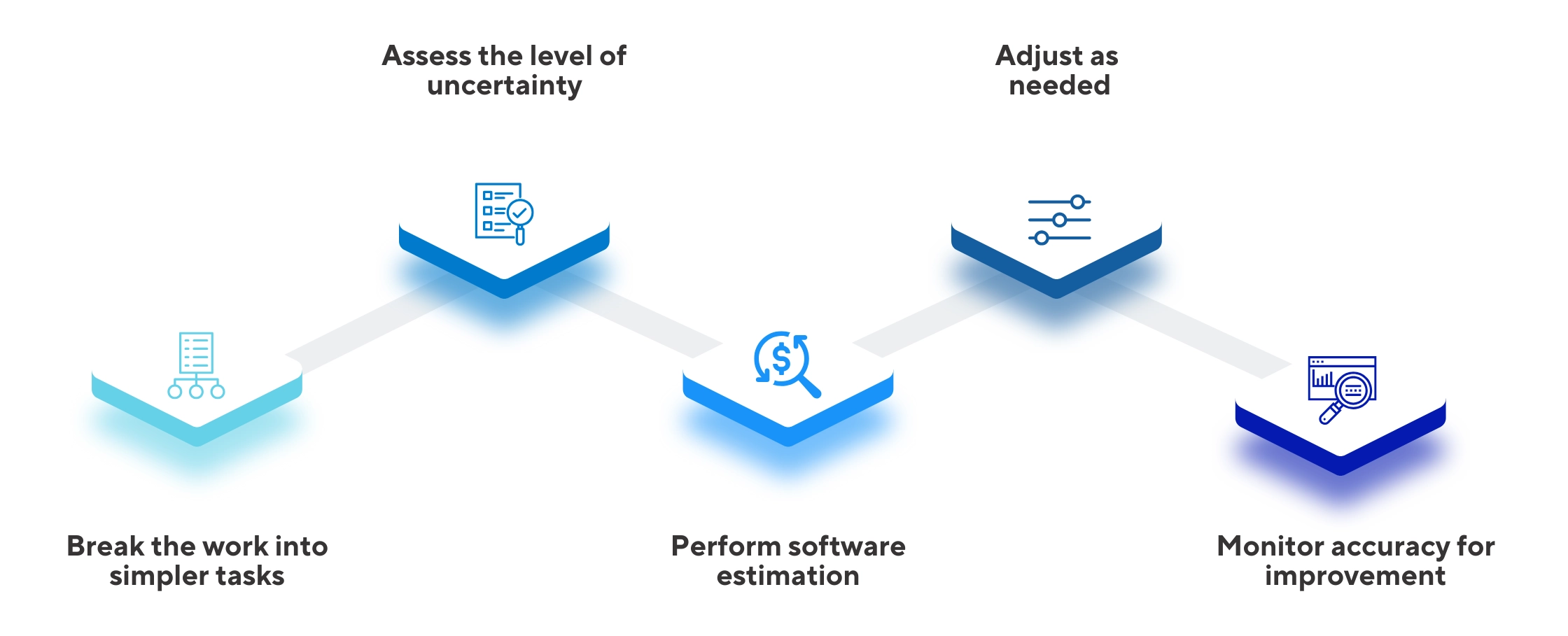
1. Break the work into simpler tasks
The foundation of nearly any software estimation technique is breaking down work into smaller tasks based on complexity. Here is the reference on how we categorize them using the following sizes:
|
Complexity |
Time |
|
Small |
1 day |
|
Medium |
3 days |
|
Large |
1 week (5 days) |
|
Extra-large |
2 weeks (10 days) |
To some extent, the names and numbers used in software estimation are arbitrary. The key is to choose a scale and stick with it consistently over time to improve accuracy. While these labels align with how I approach work, different time scales or even story points can work just as well. The specific names don’t matter—what does matter is using real wall-clock time. Here’s why:
- Map complexity to actual time units. The goal is to arrive at a realistic calendar-time estimate (e.g., “4–6 weeks”), so the mapping should be as precise as possible.
- Use real working hours and days. Avoid idealized “programmer days” that assume engineers are coding for a full eight hours. In this system, a small task should genuinely take about four hours, factoring in meetings, interruptions, and other responsibilities.
- Capture realistic expected times. Avoid both excessive optimism and unnecessary pessimism. If a task will likely take three days but could be completed in one under perfect conditions, classify it as medium. Likewise, don’t inflate a medium task to large just to play it safe—stick to what’s most probable.
The more granular the breakdown, the more accurate the overall software estimation will be. If done effectively, most tasks should fall into small or medium categories, with only a few large ones and ideally no extra-large tasks. However, this refinement doesn’t need to happen all at once. Initial rough estimates may include tasks that are too broad, which can then be broken down further to improve precision later.
2. Assess the level of uncertainty
If you were to stop here and simply total up the estimated task times, you’d get a reasonable estimate—but it wouldn’t fully capture the uncertainty inherent in software development estimation. And as discussed earlier, that’s crucial. An estimate of “20–30 days” conveys a very different level of confidence than “5–45 days,” even though both have the same midpoint of 25 days.
The next step, then, is to account for uncertainty. While you might consider capturing both best-case and worst-case scenarios, this approach is not always the most practical. Instead, we’d suggest focusing on expected-case and worst-case. Delivering ahead of schedule is rarely an issue, and in many cases, the best-case estimates almost never materialize. However, it is crucial to account for the possibility of delays. For this reason, the uncertainty system begins with the expected time (determined earlier) and then applies an “if-things-go-wrong” multiplier to reflect potential setbacks
|
Uncertainty Level |
Multiplier |
|
Low |
1.1 |
|
Moderate |
1.5 |
|
High |
2.0 |
|
Extreme |
5.0 |
The “multiplier” in this context refers to a scale factor applied to the estimated duration to generate a pessimistic estimate.
For example, if you have a medium-length task with high uncertainty, you might think, “I expect this to take 4 days, but it could take up to 8 days” (4 × 2.0). On the other hand, a large task with low uncertainty might mean, “I expect this will take 6 days, but it could extend slightly into the seventh day”
Just like with time estimates, the specific labels and multipliers are arbitrary. You may find these multipliers effective, but using different ones is fine—as long as you choose a system and stick with it.
Also, as with time estimates, your goal should be to minimize uncertainty. If you find yourself assigning too many high or extreme uncertainty estimates, it may be a sign that you need to refine and iterate on your software development estimation process
3. Perform software estimation
At this point, it’s simply a matter of applying the math based on the defined complexity and uncertainty levels. This will result in a detailed software estimation that looks like this:
|
Tasks |
Complexity | Uncertainty level | Expected time (days) | Worst-case estimate (days) |
|
Optimize query performance |
High |
Moderate | 5 |
7.5 |
|
Implement caching mechanism |
Medium |
High | 3 |
6 |
|
Update UI button styling |
Low |
Low | 2 |
2.2 |
|
Overhaul legacy system architecture |
High |
Extreme | 5 |
25 |
4. Adjust as needed
A wide range of estimates might be acceptable if the goal is simply to set general expectations. However, if external factors come into play—such as another project depending on this one’s completion, or a marketing team needing a reliable timeline for an upcoming conference—such a broad range may not be practical.
Reviewing the task list, it should be clear where the uncertainty originates. A single task with extreme uncertainty—such as “overhaul legacy system architecture”—can significantly impact the overall variance. This happens a lot: most of your project might consist of straightforward, low-uncertainty tasks, but a few highly uncertain ones can create all the variance.
Another common issue is when a timeline is dominated by a few extra-large, high-complexity tasks. If those tasks are also risky, your software project estimation becomes even broader. Even if they aren’t highly uncertain, having too many massive tasks makes it tough to break things down into a more detailed timeline—like tracking where you’ll be at the end of each month in a six-month project.
In these situations, you’ll need to refine your software development estimation by breaking down those extra-large tasks into smaller ones and finding ways to reduce uncertainty on the high-risk tasks. Of course, this isn’t easy – large tasks remain large because breaking them down is not always straightforward, and risky projects remain risky due to unresolved questions.
A practical approach is to allocate time specifically for scoping and de-risking, rather than focusing solely on completing the project. One effective method for this is time-boxing—setting a fixed period (typically 1-2 weeks) to refine the scope or mitigate uncertainty. During this time, efforts may include:
-
- Research: If a task has been done before, research can help develop a playbook and reduce uncertainty. For example, migrating a service from AWS to Azure might initially seem like a high-complexity, high-risk task. However, since others have completed similar migrations, gathering insights from their experiences can help break the task down further. In smaller organizations, this might require reaching out to external experts, but it remains a viable approach.
- Spikes: In agile software development, spikes are time-boxed exploratory efforts aimed at reducing uncertainty. They involve experimenting with a potential solution—often by developing a small, disposable prototype—to gather insights before making a full commitment. For example, instead of immediately tackling a full AWS-to-Azure migration, a spike could focus on migrating a smaller, less critical service first. The lessons learned from this trial run would then help refine the approach and estimation for the larger, more complex migration.
- Just do it: Sometimes, the most effective way to reduce uncertainty is simply to dive in and start working. Setting aside a fixed period—such as one or two weeks—to tackle the task head-on can quickly provide clarity. For instance, if five days are spent reticulating splines, and at the end of that period, 50% of the work is complete with a clear path forward, then uncertainty is significantly reduced.
5. Monitor accuracy for improvement
Finally, it’s essential to track the actual time spent on tasks as the project progresses. This creates a feedback loop—allowing comparisons between initial estimates and real outcomes—to continuously refine and improve estimation skills over time.
For instance, by the end of the project, the final breakdown might look something like this:
|
Tasks |
Complexity | Uncertainty level | Expected time (days) | Worst-case estimate (days) | Actual (days) |
|
Optimize query performance |
High |
Moderate | 5 | 7.5 |
10 |
|
Implement caching mechanism |
Medium |
High | 3 | 6 |
3 |
|
Update UI button styling |
Low |
Low | 2 | 2.2 |
1 |
|
Overhaul legacy system architecture |
High |
Extreme | 5 | 25 |
20 |
Analyzing the table, it becomes clear that optimizing query performance may actually be a high-uncertainty task, and some uncertainty could likely be reduced in future caching mechanism implementations.
This is why, even though complexity and uncertainty classifications are somewhat subjective, it’s crucial to adopt a consistent model. Changing the definitions midway would require recalibrating all future software estimation, making the process less reliable.
How Team Dynamics Influence Software Estimation Success
The work environment plays a crucial role in the accuracy of software project estimation. A culture that fosters collaboration, open communication, and learning from mistakes empowers development teams to provide more reliable estimates.
If you have the opportunity to shape your company’s culture, consider these key factors:
- Knowledge sharing & collective intelligence: Teams that encourage open discussions and knowledge sharing leverage collective expertise, leading to more realistic and comprehensive estimates. Experienced team members can provide insights on potential risks, while newer members bring fresh perspectives
- Emphasizing continuous improvement: When learning and growth are prioritized, teams naturally refine their software estimation skills over time. Mistakes should be treated as learning experiences, with proper documentation and post-mortems to prevent repeated errors.
- Embracing experimentation and adaptation: A flexible work environment that welcomes change enables teams to explore new techniques, methodologies, and tools. The industry evolves rapidly, and staying open to innovation helps improve software project estimation accuracy
Summary
Software development estimation is inherently challenging due to multiple factors—technology complexities, people dynamics, evolving requirements, and external dependencies. Despite these challenges, estimation remains essential for planning, resource allocation, and managing stakeholder expectations.
The software estimation process we’ve applied and found effective includes breaking down work into simpler tasks, assessing the level of uncertainty, making calculated estimates, adjusting based on new insights, and continuously monitoring accuracy for improvement. While no estimate is ever perfect, refining the process over time leads to better predictability and smoother project execution.
Need help improving your software project estimation process? Contact us today to see how our expertise can support your team!